In this article, I will discuss my research on algebraic and topological aspects of NLP. My main focus is on understanding the topological structure of embedding manifolds induced from deep neural models of natural language data. I am particularly interested in the development of approaches to study high dimensional representation spaces through the lens of homotopy and homology theories. This will be a general overview and a high-level introduction. Future articles will go into more mathematical and algorithmic details.
In 1872 Felix Klein was appointed as professor of Mathematics at Bavarian University of Erlangen.
As customary in Germany during that time, part of the inauguration process involved giving a public lecture and a preparation of a research prospectus.
The ideas hinted at in Klein's inaugural address, and expounded in his research prospectus (under the title "Vergleichende Betrachtungen über neuere geometrische Forschungen" - "A comparative review of recent researches in geometry”) started what is known as the Erlangen Program in history of Mathematics.
The core goal of the program was to formalise geometry as the study of invariants under algebraically defined groups of transformations.
For many centuries geometry was limited to the exploration of the logical consequences of axioms described in Euclid's "Elements".
The 19th century brought an avalanche of novel ideas due to Gauss, Riemann, Lobachevsky, and others.
These ideas led to the development of non-Euclidean geometries.
The Erlangen program provided a common framework organizing these new approaches, and developed a unified description of all geometries in the language of abstract algebra.
The power of this new approach is most evident in the realm of theoretical Physics, where mathematicians such as Hermann Minkowsky formalised Einstein's theory of relativity in this new language of geometry.
In the following decades cosmologists were able to derive basic laws of nature from group theoretic description of geometry, and particle physicists showed that the standard model of elementary components of matter can be described as irreducible representations of a symmetry group.
A new generation of Mathematicians generalized Klein's ideas into Category Theory - a unified language connecting branches of Mathematics.
Simultaneously due to pioneers such as Poincaré, a new branch of knowledge, called topology, developed out of ideas in modern geometry.
With the language of Category Theory and lessons learned during the Erlangen Program, a series of insightful connections between the realms of topology and algebra was developed.
This new field, known in modern Mathematics as Algebraic Topology, provides a powerful apparatus of new invariants used to describe high-dimensional manifolds.
In recent years, the field of Artificial Intelligence (AI) went through a renaissance of its own, resembling the situation in geometry at the time Felix Klein gave his inaugural address in Erlangen.
This new approach to AI is based on connectionist ideas of neural networks and deep learning.
The success of these approaches can be attributed to two factors: ability to extract informative representations from raw data, and the employment of gradient based parameter optimization techniques.
It is arguably the former factor, which led to the surprising success of deep learning in modelling natural data such as images and human languages.
Similarly to 18th century geometry, AI is missing a unified framework through which various deep learning architectures can be explained and analyzed.
My current research in AI is a step in this direction.
Because of the fundamental nature of the problems involved, it is a challenging research goal, and therefore provides ample material for exploration in my current and future research endeavours.
The long-term extension of the ideas introduced in this work is to formalize a unified mathematical language for explaining the properties of neural models of natural language data.
In this brief manuscript I attempt to introduce on a high level the basic ideas behind my current work in Natural Language Processing, but the methodology is general, and applicable to other types of data and AI systems.
I am principally interested in the development of approaches to the study of representation manifolds in neural language models through the lens of algebraic topology.
In particular, I probe the internal structure of linguistic unit representations arising in such models, and the learning dynamics involved in their induction.
I also develop a representation of raw corpus data as a geometric object (which I call the word manifold), whose topology encodes the n-gram patterns of words in context.
Simultaneously, I study a dual object (which I call the context manifold) which forms another view of the same natural language data.
In this perspective, the elementary units under study are n-grams of words themselves, and their relationships (encoded in the topology of the context manifold) are determined by the composition of the n-grams.
These two manifolds are intimately related, and provide complementary perspectives on linguistic structure expressed by the corpus.
I explore their intrinsic properties, their relation to each other, and their influence on embedding manifolds induced from the corpus by neural language models trained on their underlying data.
I then propose a unified approach to classification of Natural Language Processing (NLP) systems based on homology theory of manifolds, and show that there is a natural correspondence between topological descriptors of corpus data and choices of neural architecture within the language model.
Additionally, I describe how these methods can lead to parameter-efficient NLP models, and early stopping criteria for learning from natural language data.
The final contribution of this project is a formalization of my theory of neural language models in the language of Category Theory (inspired by categorification arising in pure mathematics such as ).
Throughout this work concepts from Mathematics, Computer Science, and Linguistics are utilized to develop computational apparatus for examining linguistic structure encoded by corpus data.
A quotation attributed to the famous Dutch computer scientist Edsger W. Dijkstra says "Computer Science is as much about computers, as Astronomy is about telescopes.".
In this research project, I attempt to construct a telescope through which we can view natural language data.
Although the object of study is not the telescope itself, but the phenomena I wish to examine through its lenses, I need to be careful and precise during its construction, in order to avoid impurities that could generate optical illusions.
For this reason, I develop all code from scratch without relying on complex software libraries that could contain such impurities.
This includes the development of a fully functional deep learning framework implementing dynamic computation graphs, and automated differentiation of tensor expressions.
I also develop tools for topological analysis of corpus data and the generation of word and context manifolds.
I then construct neural language models and train them on standard corpus data using only the code developed for this project.
The project is thus self-contained, which allows the interested reader to fully understand all of its components.
More importantly, it gives me full control over the tools I use, and the ability to do detailed ablation studies in experiments exploring the relationship of corpus data to its representation manifolds in neural language models.
I hope that the theoretical methodology, mathematical apparatus, algorithmic ideas, and code implementation frameworks developed within this research program form a paradigm for my future research.
Thomas Kuhn examined the processes leading to the formation of new paradigms in his seminal work under the title "The Structure of Scientific Revolutions".
A new paradigm usually forms after a period of crisis.
The field of Artificial Intelligence, and Natural Language Processing in particular, has been through a series of crises in the past decades.
The most recent crisis in AI culminated in the Deep Learning Revolution of recent years.
Although the field of NLP has largely adopted deep learning methods, it still lacks organization and a unified language of discourse.
A reader of current literature in this field will find a zoo of diverse neural architectures, heuristics, and hacks that sometimes resemble Alchemy before it turned into Chemistry.
I believe that the field of NLP is in a pre-paradigmatic stage.
This is an exciting time to be involved in academic discourse.
I hope that my work can be viewed as a contribution to the formation of a coherent foundation for a future paradigm in this area.
"I think that people who assumed thoughts are symbolic expressions made a huge mistake.
What comes in is a string of words, and what comes out is a string of words.
Because of that strings of words were the obvious ways to represent things, and they thought that what goes on in between was some formal sequential language like a string of words.
I think that what's between is nothing like a string of words.
I believe that the idea that thoughts must be in some kind of language is as silly as the idea that understanding the layout of a spacial scene must be in pixels.
However, what's in between isn't pixels or symbolic expressions.
I think thoughts are these high dimensional vectors that have causal powers - they cause other vectors, which is utterly unlike the standard view involving symbolic calculi."
- Geoffrey Hinton
Academic research in a field such as Computer Science, which often deals with subjects on the interface between science and engineering, can be viewed from two complementary perspectives.
One view relates to more pragmatic concerns, focusing on the development of ever more advanced systems pushing State of the Art (SOTA) to incrementally higher results.
These efforts can take the form of improving implementation efficiency of currently existing models, or developing models that achieve improved results in a given domain of practical interest.
I call this view of computer science research "the technologist's perspective". It has been the prevalent perspective within the field of Artificial Intelligence during the past decade.
Statistical Machine learning, and subsequently Deep Learning methods in AI advanced SOTA to previously inconceivable heights in a variety of application areas.
In some instances, AI systems engineered for standard tasks defined on community datasets achieved superhuman accuracy scores.
The success of Neural Information Processing Systems in the field of Artificial Intelligence is undeniable.
However, some researchers begin to question whether the technologist's approach is all we should be focused on.
One category of reasons for this criticism of purely technological view of research is philosophical.
What are the ultimate goals of an academic field?
In case of AI, we could take a conservative stance, and define it as the engineering of systems that perform tasks that normally require human intellect.
In this case, improving SOTA accuracy on a narrowly defined task advances the goals of the field.
A broader view might define AI as the study of computational processes leading to the emergence of intelligent behavior.
Under this definition, exploratory projects aimed at increasing our understanding of such processes advance this goal, whether they lead to immediate improvements of accuracy on currently defined AI tasks or not.
Alternative reason not to focus solely on performance improvements has to do with the fact that such performance metrics give only an indirect indication of whether the system under question approaches the goal it was designed for.
Does a neural language model generating English text truly understand the meaning of words, or does it use cheap tricks to appear coherent ?
Does an image classification system understand the difference between objects it classifies ?
The second view of research goals in such a field focuses on the more theoretical aspects of the discipline.
I call it "the scientist's perspective".
It is the view mainly taken in the work presented here.
A major reason for pursuing this avenue of scientific inquiry is to gain a deeper understanding of data and algorithms.
One common criticism of pure technologist's approach is that most SOTA models are complex neural systems that act as black boxes.
It is hard to understand their inner workings, and often impossible to justify decisions made.
As systems based on these algorithms are applied to a growing number of problems of practical interest to society, interpretability of their decisions becomes a major concern.
My work investigates some of the fundamental questions relating to the structure of data and algorithms used in such systems.
Artificial Intelligence is currently split into multiple fields focusing on narrow areas of interest.
Some of these areas correspond roughly to human faculties such as the ability to understand visual scenes, interpret audio signals, or communicate in natural languages.
The problems I am working on are most relevant to this latter area - Natural Language Processing (NLP) - although my focus is less on practical applications and more on gaining fundamental insights into the structure of natural languages.
This type of research is usually labeled as Computational Linguistics - an interdisciplinary area of scientific inquiry at the intersection of Computer Science and Linguistics.
However, the methods developed here are not limited to linguistic data, and exploring the application of such analyses to other types of data is a topic I wish to explore in future research.
My analysis leans more towards the mathematical and algorithmic aspects of language than that of classical linguistics, therefore it is oriented more towards Computer Science, and Artificial Intelligence in particular.
My current work can be described as an investigation into geometry of natural language representations in vector spaces.
In particular I am interested in connectionist mappings of linguistic units into high-dimensional real manifolds.
There are many possible choices for what parts of natural language data to derive representations from, what vector space should contain said representation, and what do we mean by geometry.
In this work, the representations come from mappings induced by deep neural network models designed for the task of language modeling.
The codomains of these mappings will be real vector spaces of several hundred dimensions, and the mappings themselves are approximated by the neural embeddings learned through back-propagation on raw corpora of natural language text. As a proxy to understand the geometry of these representations, I use methods derived from mathematical theory of manifolds. In particular I employ category theoretical invariants of manifolds inspired by methods developed in the field of algebraic topology for classification of such structures.
I also apply the tools developed while working in this area to projects involving natural language data.
These projects draw on ideas from multiple disciplines.
Some of the most prominent theoretical foundations for my work are as follows.
First, from Computer Science, I employ various methods of neural information processing and deep learning.
Second, from Mathematics, I borrow the powerful apparatus of algebraic topology and manifold theory.
Third, from Computational Linguistics, I focus on the distributional hypothesis and modeling of raw text corpora.
My basic goal is to study topological aspects of neural language models.
These models are trained on raw natural language text, and their primary mechanism involves deriving informative vector space representation of such data.
In the case of a pure language model, the representations are informative in the sense of predicting the context in which words appear (although we could also derive representations for some specific downstream tasks such as question answering).
In the simplest form, this would involve guessing which words were removed from a sentence sampled from the corpus.
Because of this, the resulting embedding manifold has a natural relation to the corpus, and its structure must be influenced by the co-occurrence patterns of words in context.
This leads to three natural research directions.
These directions can be motivated by three basic questions that naturally arise from three parts of a neural language model: corpus data, distributed representations, and the link between them created by the neural architecture used.
What questions do I want to answer?
First, on the raw data side, I consider the following question.
What are natural notions of topology for raw text data, which are sensitive to the linguistic structure encoded in the corpus?
I develop a straightforward and efficient procedure for the generation of topological manifolds associated with the corpus, which I will refer to as word manifolds.
Furthermore, the topology of the resulting manifold encodes n-gram patterns in the text from which it was derived.
Because this manifold is constructed through an inductive combinatorial process, it allows for an elegant algorithm determining its homotopy type, which I implement using efficient BLAS subroutines.
A natural question that arises in this context, is something that is asked whenever group theoretic methods are used in science.
What are the symmetries of corpus data with respect to this structure?
In other words, how can we perturb the text, without changing the homotopy type of the word manifold?
I use this as a framework to classify textual corpora.
I also come back to the question of text topology, after developing the theory of representation manifolds in neural language models.
There, I present a second procedure for assigning topological structures to raw text data, which links it directly to the language model trained on that data.
Second, on the representation side, I study topological structures in the induced embeddings within a neural language model trained on the given corpus of raw text.
Since distributed representations (extracted from the hidden states of a deep neural network model) are floating point tensors (which can be thought of as elements of a vector space over \mathbb{Q}), the embedding manifold comes with a canonical notion of topology (by considering open \epsilon-balls at each point).
I then build Vietoris-Rips complexes over those embeddings, and employ tools from TDA, such as persistent homology modules, to extract topological features of the representation space.
The question I am predominantly interested in, is how does the topology of the representation manifold relate to the topology of the word manifold.
Given a trained language model, we can also pull back the topology of the induced embedding manifold back to the raw corpus data by assigning a sequence of manifolds (simplicial complexes) that summarize the topological structure of the representations.
Third, on the model side, the link between the two topological spaces discussed is clearly determined by the neural architecture used.
In order to formalize this notion mathematically, I think of the neural language model as a mapping from the category of word manifolds (as defined by the simplicial complex constructions on raw text) with continuous maps (as defined by topological notion of continuity in the realm of simplicial complexes) and the category of embedding manifolds that come with an ambient metric space.
I then explore the idea of a good LM as a functor between these categories.
Category theory was developed precisely to formalized such relationships, and the fundamental idea here is that an isomorphism in the domain of a functor should translate to an equivalent notion of an isomorphism in the codomain.
Hence the symmetries of text with respect to representation in a neural language model are those perturbations of corpus data, which lead to homotopy equivalent word manifolds, and the right neural architecture to model a corpus should respect that symmetry in the sense that the resulting morphisms of the embedding manifold should generate homotopy equivalent structures on the representation side.
We can then classify neural architectures based on their ability to approximate this functoriality.
Why are the problems posed in these questions significant?
Next, I consider the importance of the subject matter explored here, in the context of current research within the field of Artificial Intelligence, and Natural Language Processing in particular.
In the past decade, Deep Learning approaches have dominated the field of
Artificial Intelligence across a wide a array of domains.
Recent developments in neural information processing methods sparked a
revolution in Natural Language Processing , which resembles advances made
in Computer Vision at the beginning of this new chapter of AI development.
This progress was made possible through increasingly more advanced
representation methods of natural language inputs.
Initially shallow pre-training of early model layers became standard in NLP
research through methods such as word2vec .
Subsequent progress followed trends similar to those in CV, which naturally led
to pre-training of multiple layers of abstraction.
These advancements resulted in progressively deeper hierarchical language representations, such as those derived using self-attention mechanisms in transformer-based architectures .
Currently SOTA NLP systems use representations derived from pre-training of
entire language models on large quantities of raw text, and often involve
billions of parameters.
The research undertaken here is relevant to these developments in two major ways.
First, although modern language modeling methods, based on deep neural networks, improved perplexity scores and downstream task performance, they are considered to be over-parametrized black boxes.
Furthermore, there is no theoretical explanation as to why certain neural architectures perform better than others on various natural language data sets.
Therefore, more foundational research aiming at understanding the structure of linguistic unit representations arising in these models, and their relationship to the raw corpus data is needed.
The second reason for such research is more practical.
SOTA neural language models are extremely inefficient.
They contain hundreds of billions of parameters and cost millions of dollars to train on raw text data.
This leads to concentration of ownership of such models to a handful of corporate research labs with large resources.
Furthermore, due to the size and complexity of these models, they can only be run on large clusters of supercomputers, and thus are not available on mobile devices or even personal desktops.
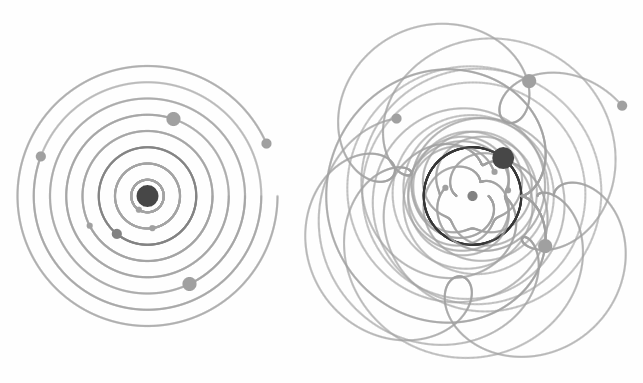
FIGURE 1Heliocentric (left) vs geocentric (right) description of the solar system.
One can view learning as the compression of data and theory together.
In this sense we learn something interesting, if we find patterns in data, which are informative towards the task at hand, and use this knowledge to design a simpler (compressed) theory.
Figure 1 shows two alternative descriptions of the planetary motions inside the solar system.
Both models can describe the data (movements of heavenly bodies) with similar accuracy.
However, the heliocentric model can represent this data with less bits of information.
Finding such efficient representations is especially important in modern NLP, where SOTA models contain billions of parameters .
Main reason for the large size of these models is the input representation, which takes up the bulk of resources.
Recent developments in deep learning literature suggest that most connections in complex neural networks are either spurious or can be replaced by approximate values.
Lines of research such as Bayesian neural networks replace exact weight values with probability distributions.
Recent work on neural tangent kernels sheds some light on the dynamics of weight space during learning .
It is even suggested that the exact values of the weights aren't as important as their relationship as a whole .
This has been taken to a more extreme conclusion in where the authors show that topology of a neural network can encode enough information that the model can perform a task with random weights.
Studying the structure of data and embedding spaces emergent in neural language modeling can lead to distillation techniques that would allow us to compress these large language models into smaller architectures with equivalent performance.
Understanding the structure of representation manifolds induced by neural language models is the first step on the path towards deriving more parameter-efficient architectures.
In my work, I employ ideas from Category Theory and Algebraic Topology to understand and classify components of deep neural language models and probe the structure of their representation spaces.
As it currently stands, such approaches have not been applied in the field of Computational Linguistics.
In analogy to an image manifold, I introduce the notion of the word manifold and analyze its structure with tools from homological algebra.
Future research will build on lessons learned in this work, to develop embedding features that would allow us to compress natural language data and arrive at smaller, more efficient neural language models.
I hope this work inspires others in the Natural Language Processing community to pursue this path as well.
Because the methods introduced in this project are novel in the field of Computational Linguistics, and topological aspects of neural information processing systems have not been sufficiently investigated to this date, there is a high degree of potential for uncovering patterns missed by currently used methods.
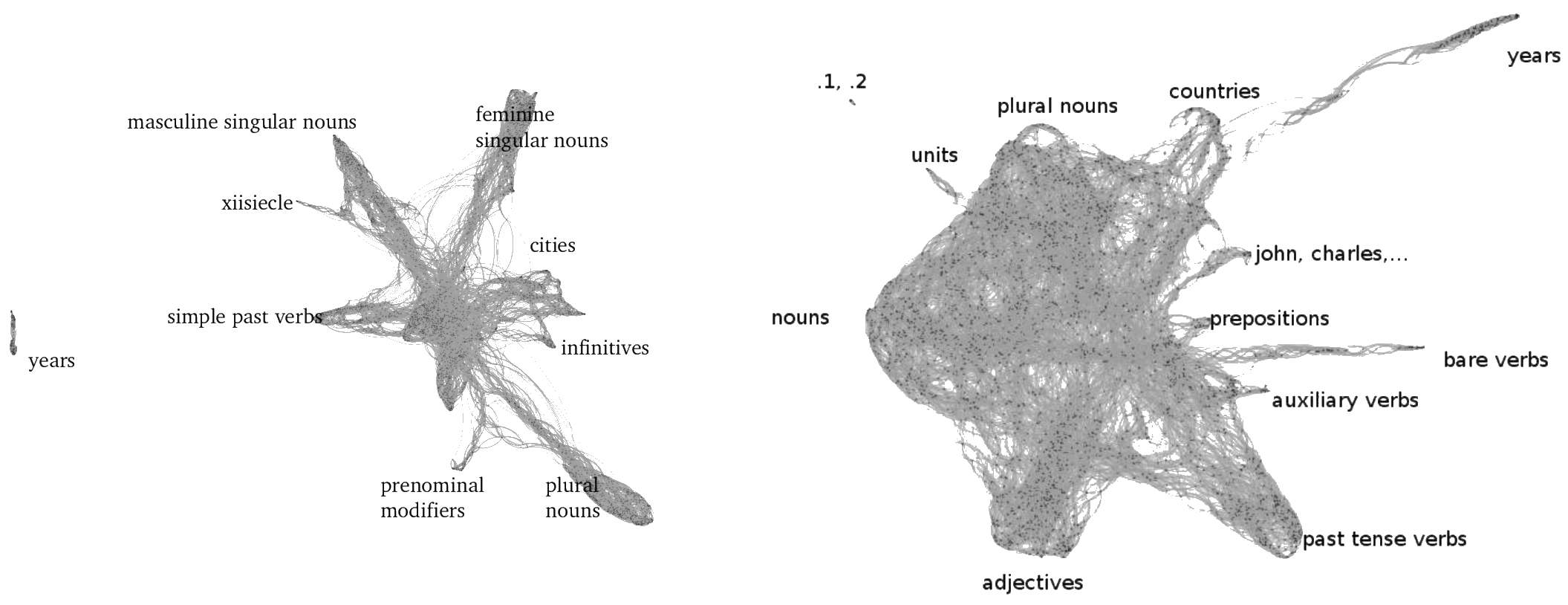
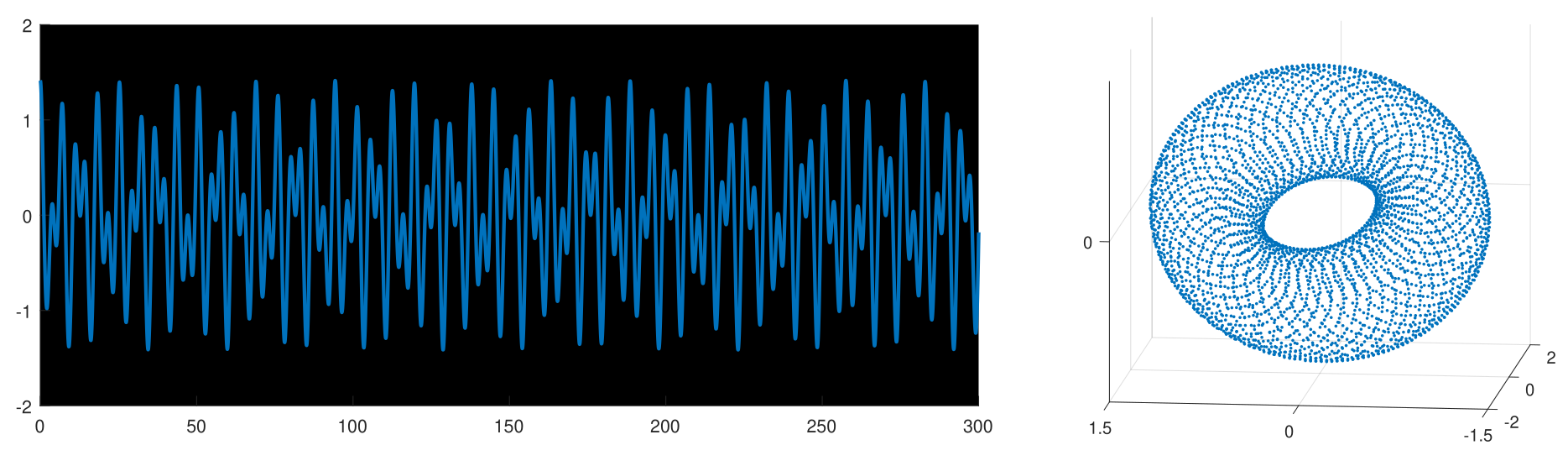
There are types of patterns both in raw data, and in representation spaces induced by deep learning models, that are often lost in statistical analyses, but produce a clear signal when viewed from a topological perspective.
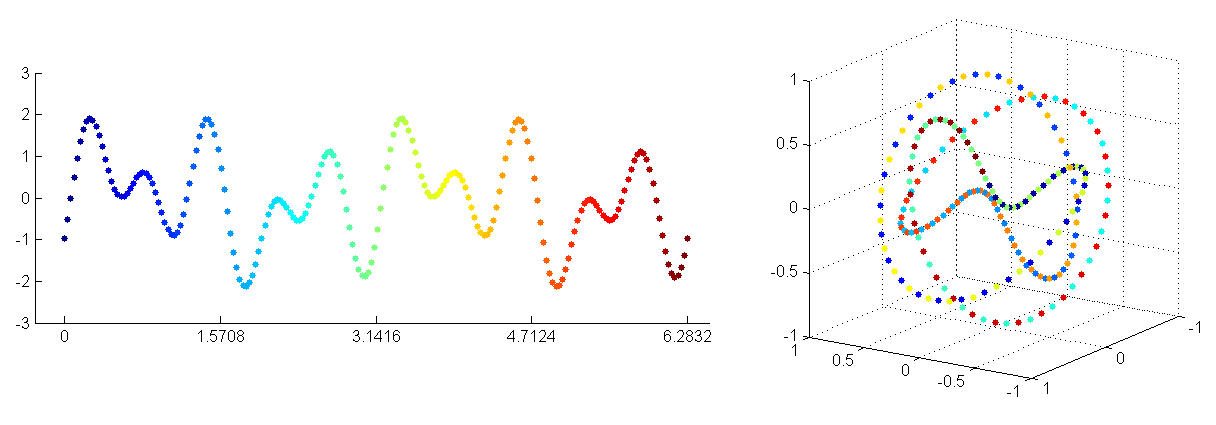
For instance, figure 2 shows a time series of values which is hard to interpret directly, yet makes immediate sense after sliding a window of three values and re-representing this series as a point cloud in a three-dimensional ambient embedding space.
I use similar perspective in a higher-dimensional setting to analyze how a hidden state of a neural language model (a time series of tensors) evolves when computing contextualized word embeddings from a neural language model over a corpus of raw text.
Finally, the methodology developed in my work can be applied to other settings outside of Computational Linguistics. The predominant apparatus employed in computational social sciences is based on complex network theory, which can be described as the study of graphs.
Graphs are a special case of a simplicial complex of dimension one.
The methods introduced here, generalize graph theory to higher dimensions.
For instance, ranks of homology groups in zeroth dimension compute connected components, and in dimension one we can count cycles within the network.
However, simplicial complexes are strictly more powerful as they can model more complex social interactions.
Instead of focusing only on pairwise relationships, we can include higher dimensional structures that model complex interactions among groups of people.
This is a topic I leave for future research.
How are we equipped to address them?
Finally, I discuss the feasibility of this project in terms of our ability to make a significant contribution towards answering the posed questions.
First, on the technology side, there has been significant progress made in recent years in developing both hardware and software components necessary to perform the types of computation required in this project.
These advancements take form of cloud computing services with GPU hardware, as well as algorithms efficiently implementing neural language models with distributed representations of linguistic units.
Second, on the theory side, methods of topological data analysis and computational algebraic topology have experienced rapid development, fueled by their utility across a range of applications (especially an initial success in neuroscience).
These background developments, which I have been tracking over recent years, combined with my personal education in the fields of Mathematics, Computer Science, and Linguistics, allow me to develop approaches based on these ideas in the field of NLP, where such methods have not been extensively researched.
I believe that this setting provides an opportunity to apply my unique combination of skills in an unexplored subject with significant impact potential for the larger field of NLP.
I have been developing theory and code to address the stated research problems.
While working on the material for this project, I have also experimented with applying topological viewpoint to tangential research projects in the wider area of NLP.
These include results on incorporating topological information on supra-lexical level.
This can be done in practice via an adjacency matrix that determines relationships between parts of the document (usually sentences or paragraphs).
Here I introduce a test model for multi-document question answering.
The goal of this experiment wasn't to surpass SOTA results on QA, but rather to evaluate a possible contribution of topologically conditioned document representations for a task of practical interest in current NLP research.
However, to my surprise, introducing topological information into document embedding resulted in a model that performs competitively with SOTA systems, while avoiding costly pre-training of over-parametrized language models.
The topologically informed document representation results in 99% reduction in parameter space without any sacrifice in task performance.
This led me to the realization that topologically informed representations can produce more sustainable NLP systems by significantly reducing model complexity, and hence lowering the cost of model training.
Results from my prior work have consistently hinted at the unexplored utility of topological methodology to uncovering patterns in natural language data.
I am convinced that the scope of this project provides the right balance of complexity and difficulty to produce a coherent body of research with a novel contribution to a subject of importance in the field of Artificial Intelligence.
Over the past century, we saw an emergence of new branches of Mathematics exploring the structure of high dimensional objects.
These ideas emerged initially from the Erlangen Program outlined by Felix Klein in his seminal work on the formalization of geometry as the study of invariants under algebraically defined groups of transformations .
The body of research produced through this program led to the development of category theory as a unifying language connecting previously isolated branches of Mathematics.
A particularly powerful type of such category theoretical relationship is expressed by the homotopy and homology functors linking the realms of topology and abstract algebra.
These notions belong to the branch of Mathematics known as algebraic topology, which has been in accelerated development over the past century, producing a set of powerful tools for probing global and local properties of manifolds.
In recent years advances in hardware, availability of large data sets, as well as innovation in architectural and algorithmic design, enabled successful application of methods from manifold theory to real-world data.
Following this general trend, I am currently developing computational apparatus based on ideas from algebraic topology to gain deeper insights into the structure of linguistic data and its representations within neural language models.
In this section I outline the goals of my research.
Develop methods to study the structure of natural language data from a topological perspective.
The first goal of this project is to build a bridge between topology and language.
Such a connection will then allow me to adapt powerful machinery developed over the past century in pure Mathematics for the study of topological manifolds, and employ it for the study of linguistic structure encoded in corpus data.
In particular, I am concerned with the development of algorithms for associating topological manifolds to raw corpus data.
The requirements for these algorithms is that the topology of the resulting manifold encodes word co-occurrence patterns, and that no extrinsic information is imported in this association process.
The distributional hypothesis, which forms a fundamental assumption behind neural language model training, states that syntactic and semantic relationships between words can be inferred from their context (i.e. co-occurrence patterns with other words in the corpus).
I use this idea as a basis for my construction of a CW complex, where 0-dimensional cells are identified with word tokens, and higher-dimension features are determined by the n-gram patterns within a given corpus of text.
The resulting topological structure will be called the word manifold and exploration of its properties is one of the primary goals of this project.
Similarly to the word manifold, I define and study a dual object, which I will call the context manifold.
This object considers contexts as the atomic elements, and relationships between them are determined by words that appear in them within the corpus.
I then explore the duality arising from these two views of natural language data.
The goal of this part is to understand the relationship between these two viewpoints, and classify symmetries of text that preserve the homotopy type of the associated topological manifolds.
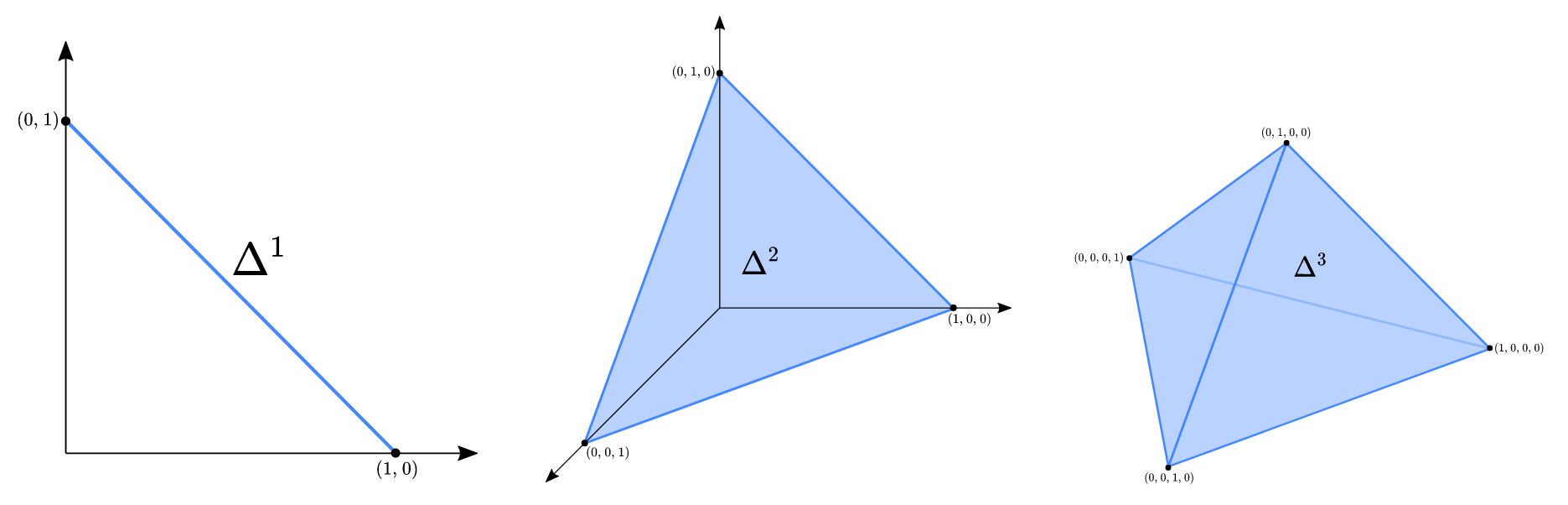
FIGURE 3Visualization of a simplex in different dimensions. The algorithm I develop in the first part of this project maps a corpus of natural language text onto a simplicial complex. Simplices can be represented geometrically as convex hulls of standard basis vectors in \mathbb{R}^n. In the case of the word manifold the 0-simplices (i.e. vertices) correspond to the lexicon, and higher dimensional simplices come from n-grams of words found in the corpus. The gluing together of simplices into a topological space, as well as the definition of the boundary operator is determined by co-occurrence patterns of words in context.
After generating word and context manifolds, I study them using techniques derived from algebraic topology.
One of the major tools I use in this part is based on homological algebra.
Homology theory constructs functorial mappings from the category of topological spaces and continuous maps to the category of abelian groups and group homomorphisms.
In this translation homotopy equivalent manifolds induce isomorphic homology groups.
This allows us to employ powerful theorems from commutative algebra for the study of topological spaces.
Details of this construction go beyond the scope of this article, but the reader can find a good introduction in .
The resulting method allows us to generate a sequence of free abelian groups together with group homomorphisms, known as a chain complex.
\ldots \rightarrow C_n \xrightarrow{\partial_{n}} C_{n-1} \xrightarrow{\partial_{n-1}} \ldots \rightarrow C_1 \xrightarrow{\partial_1} C_0 \rightarrow 0
The groups C_i above are associated to the space under study via an inductively defined procedure that satisfies a set of straightforward axioms.
There are many possible procedures resulting in equivalent homology theories (i.e. the resulting homology groups are isomorphic).
For my purposes, I employ a combinatorial version of this theory known as simplicial homology (see figure 3).
The key property of the homomorphism \partial_\bullet above is that \forall_n \partial_{n-1} \circ \partial_n = 0, which implies that \text{im} \partial_n \subseteq \ker \partial_{n-1}.
The elements of \ker \partial_{\bullet} are called cycles, and the elements of \text{im} \partial_{\bullet} are called boundaries.
Homology of the space under study is then defined as the group theoretic quotient of cycles modulo boundaries.
H_n(C_{\bullet}, \partial_{\bullet}) = \frac{\ker \partial_n}{\text{im} \partial_{n+1}}
These groups form algebraic invariants of topology, so homeomorphic structures will result in same groups up to isomorphism.
We are often interested not in the particular groups (as the choice of generators is not canonical) but just in their ranks, known as Betti numbers, which can be interpreted as counting cavities in all dimensions of the manifold, and thus give a coarse description of its shape.
The following proposition allows us to efficiently compute the Betti numbers using basic linear algebra subprograms (BLAS libraries compiled in FORTRAN).
Proposition: Let A be an m \times n matrix, and B be an l \times m integer matrix with BA = 0. Then \ker (B) / \text{im} (A) = \bigoplus\limits_{i=1}^{r} \mathbb{Z}/\alpha_i \oplus \mathbb{Z}^{m-r-s}, where r = \text{rank} (A), s = \text{rank} (B), and \alpha_1, \ldots, \alpha_r are the nonzero elements of the Smith normal form of A.
After interpreting our chain complex as a sequence of finitely generated abelian groups, where the generators correspond to the n-grams of words extracted from the corpus, and computing the Smith normal form of the boundary map, we can extract the number of cavities in each dimension of the word manifold simply by reading the nonzero columns of the diagonal matrix in the resulting decomposition.
Analyze the topological structures in vector space representations of linguistic units.
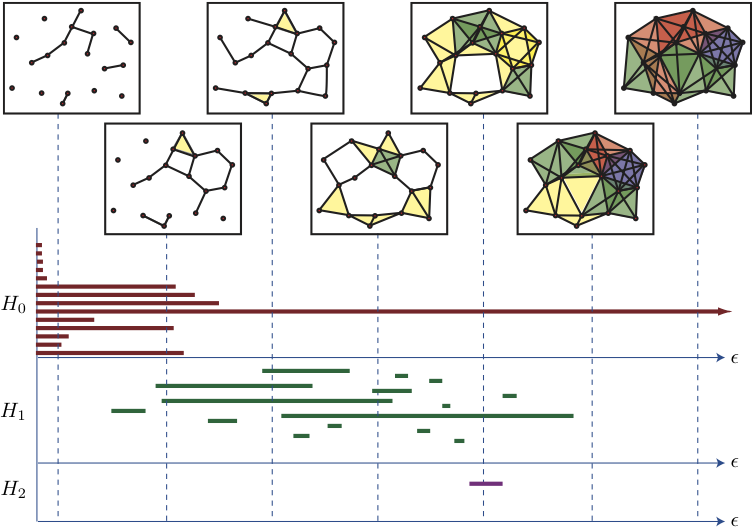
FIGURE 4A filtration of Vietoris-Rips complexes with distance parameter \epsilon on a set of points embedded in an ambient metric space, and the associated persistent homology barcodes.
Having described the raw text data from a topological perspective, my next major goal is to understand topological structure of representation spaces induced by deep neural language models trained on this data.
The first task is to understand homotopy types of learned embedding manifolds.
A major difference between the word manifold from the previous part and the representation manifold in a language model is that the former arises from discrete data without a canonical choice for topology.
In contrast, linguistic unit representations exist in a metric space which naturally comes equipped with the open \epsilon-ball topology.
I take advantage of this fact by employing ideas from computational algebraic topology and topological data analysis.
The justification for relying on this standard metric space topology is that the inner product in the ambient space already encodes syntactic and semantic relationships between words due to self-supervised learning process of the neural language model.
For this reason, topology based on proximity in the embedding space must hold a natural relationship to the word and context manifold topologies based on word co-occurrence patterns.
My goal is to understand this relationship.
Among the techniques I will use in this part of the project, are topological persistence modules from a Vietoris-Rips complex filtration (figure 4 shows a visualization of the basic idea behind the procedure).
This method will be used in several ways, which relate to how the relevant filtration of simplicial subcomplexes is obtained.
The default way of constructing filtrations is by varying a distance parameter in the embedding space.
This corresponds to relaxing similarity measure between linguistic units as computed by the neural network.
Another way is to vary window size in an n-gram language model.
Because n-gram model a fortiori contains information captured by any k-gram patterns for k < n, we can map this relationship into a sequence of topological spaces with a matching chain of inclusions.
Homology generators in the associated persistence module can then be interpreted as topological information that survives while zooming out from a narrow to a wide context window - i.e. patterns that are stable across n-gram language models.
Another set of experiments to be performed in this part of the project relates to homological properties of time series data formed by the hidden states of a language model.
When words from a corpus are fed into the neural network implementation of the language model, its hidden state vector traces out a path in the embedding space.
I am interested in interpreting topological properties of these paths, and their relationship to corpus data.
One of the algorithms used here is sliding a window over the time series of the hidden states associated to the LM, and computing topological invariants of the resulting point clouds (see figure 5 for an illustration of the underlying technique).
Additionally, my goal is to analyze the behavior of contextualized word embeddings.
These are representation methods that use trained neural language models to derive a moving embedding of each word in the context of its surrounding sentence .
FIGURE 5We can reinterpret a time series of values as a geometric object by performing a sliding window embedding . The resulting point cloud can then be interpreted as noisy samples from an underlying manifold. The topology of this manifold can be studied using tools from computational algebraic topology. It reveals intrinsic properties of the original time series that are not easily captured by standard methods.FIGURE 6Inducing topological structure from a point cloud representing noisy samples from a neighborhood of a 1-dimensional submanifold of \mathbb{R}^2
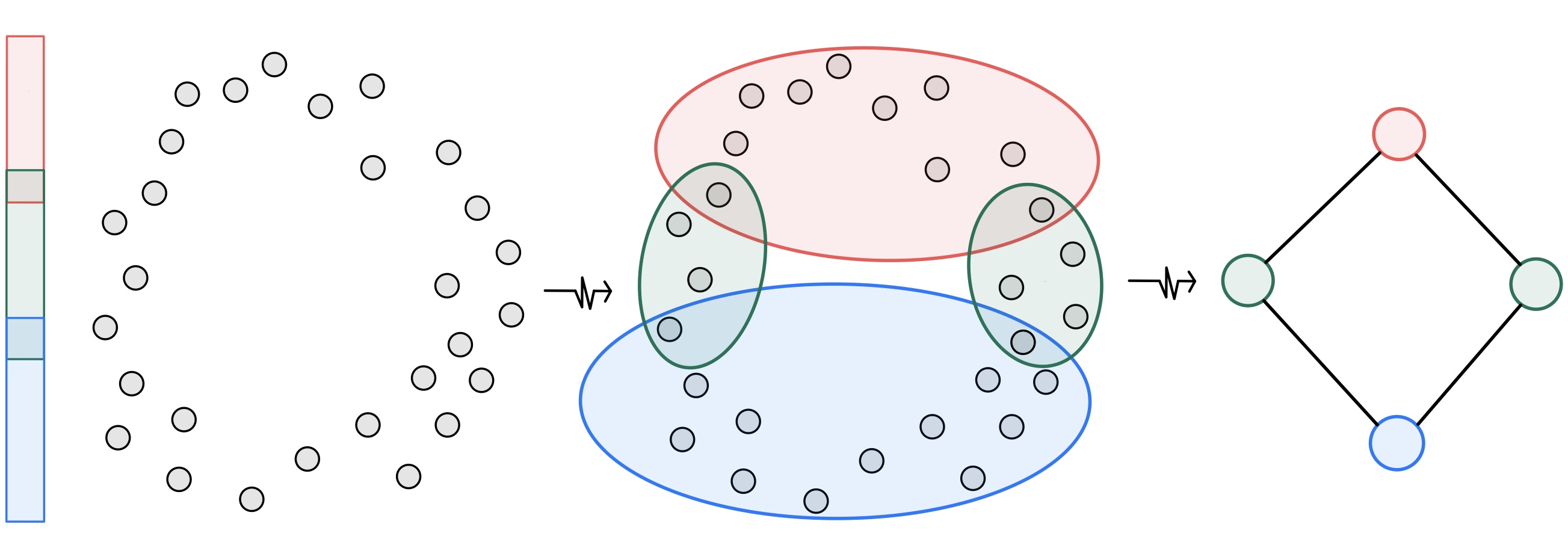
Another set of experiments that I perform in this part of the project uses a different method of measuring topology in the embedding space.
Instead of growing \epsilon balls around points directly, we can map them to a different space (usually of lower dimension), define an open cover, and then cluster the original points within the preimage of each cover set.
This produces a summary of the topological features in the embedding with a simplicial complex of a chosen dimension (e.g. a graph as in figure 6).
The gist of the procedure can be summarized as follows.
Given data points \mathbb{X} = \{x_1, \ldots, x_n\}, x_i \in \mathbb{R}^d , a function f: \mathbb{R}^d \rightarrow \mathbb{R}^m, m < d , and a cover \mathcal{U} = \bigcup_{i \in \mathcal{I}} U_i of the image f(\mathbb{X}) (where \mathcal{I} is some index set) we construct a simplicial complex as follows:
For each U_i \in \mathcal{U} , cluster f^{-1}(U_i) into k_{U_i} clusters C_{U_{i,1}}, \ldots, C_{U_i,k_{U_i}}
\underset{U_i \in \mathcal{U}}{\bigsqcup} \{C_{U_{i,1}}, \ldots, C_{U_i,k_{U_i}}\} now define a cover of \mathbb{X} ; calculate the nerve of this cover
Nerve is defined in the following way. Given a cover \mathcal{U} = \bigcup_{i \in \mathcal{I}} U_i , the nerve of \mathcal{U} is the simplicial complex \mathcal{C}(\mathcal{U}) where the 0-skeleton is formed by the sets in the cover (each U_i is a vertex) and \sigma =[U_{j_0}, \ldots, U_{j_k}] is a k-simplex \iff \bigcap\limits_{l=0}^{k} U_{l_k} \neq 0.
Finally, I consider the question of whether forcing the representation space to assume certain shape, can help the language model converge faster and with less parameters.
I develop a procedure to encourage lexical embedding to evolve into a manifold of a given homotopy type, which I call topological conditioning of the neural language model.
This is done by implementing a regularization module which penalizes the model during training, based on a score that correlates with a notion of closeness in topological structure.
I use this method to condition a deep neural language model on the homotopy type of the word manifold computed directly from the corpus.
The resulting improvement shows that topological information carries useful linguistic signal, which in turn aids convergence of the language model when trained on new data.
A question I aim to address here, is what kind of information does this topological conditioning inject into the model.
Experiments used to shed light on this question involve varying the corpus within the same language (e.g. different styles and topics), as well as varying the language on aligned corpora (e.g. French translations of English text).
Formalize the study of neural language models from the viewpoint of Category Theory.
When studying diverse branches of pure Mathematics, at some point one starts experiencing a feeling of déjà vu.
A theorem in differential geometry resembles another one in abstract algebra.
A definition in topology looks like something seen previously in combinatorics.
Sometimes one studies a proof of a theorem in number theory, and it seems like the thought pattern is similar to a proof of a seemingly unrelated proposition in logic.
It is hard to put a finger on the exact analogy, but the feeling of having witnessed similar patterns in previous studies is strong and sudden.
Category theory distills this notion of mathematical déjà vu into a formal language, that allows us to translate ideas between branches of mathematics and capture the essence of concepts that appear.
This metatheory of Mathematics, allows us to zoom out, and gain a bird's eye view perspective of the mathematical landscape.
Instead of thinking of the objects of study directly, a category theoretical perspective favors examining transformations between objects of a coherent type (a category).
A fundamental idea emerging in this context implies that any mathematical object can be characterized by its universal property, which is described in terms of morphisms between it and other objects of similar type.
A coherent translation of mathematical objects of one type into objects of another type naturally converts the morphisms between pairs of objects as well.
This type of conversion between categories is called a functor.
Given two different functors between a pair of categories we can also study a translation between them called a natural transformation.
This way of thinking results in beautiful and concise descriptions, that allow classification of concepts, and construction of bridges between initially disconnected areas of discourse.
For instance, the Seifert - van Kampen Theorem in algebraic topology can be restated succinctly in category theoretical language as saying that a commutative pushout square of fundamental groupoids (a universal property in a category associated to a topological space) is preserved by the homotopy functor.
My final goal is to lift the constructs of a corpus, distributed representation, and neural language model to category theoretical notions (such as functors, natural transformations, adjunctions, etc.).
Here, I associate one category (based on the manifolds introduced previously) to the corpus data itself, and another category to the representation spaces of such data.
A neural language model can then be cast as a mapping between these categories, and I posit that good models are those that approximate functoriality.
I explore a notion of a natural transformation between models, and use this framework to classify neural architectures for the task of self-supervised raw text language modeling.
This article introduced the general high level ideas and a roadmap for a research project in progress. Subsequent articles will introduce these concepts in detail, and present experimental results, as well as implementation code.
The exposition in future articles will follow roughly the order outlined in this general idea paper. We will start with some theoretical background. Subsequently, we will embark on a journey to explore topological features of raw natural language data by developing in full rigour the notions of word and corpus manifolds. Developing these ideas will take form of a series of articles. Afterwards, in a following series of articles, we will study the topology of vector space representations associated with this data by deep neural language models. The final set of articles on this topic will cover the category theoretic ideas and their application to NLP.
As I develop this journal further, there might be a discussion forum added for readers and collaborators. In such case, a brief post on the details of how to join such a forum will be published here as well.
Remarks
This article is an idea paper on a work in progress.