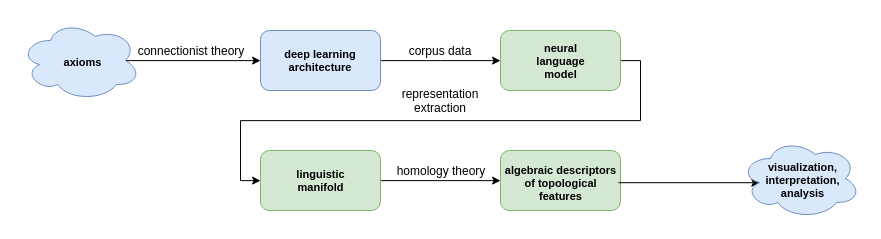
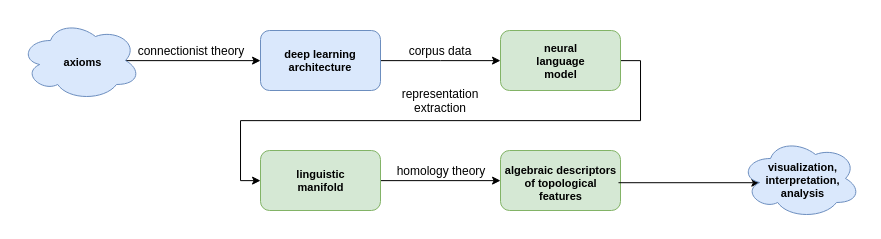
In this article, I give a general overview of a series of experiments, grouped into ten coherent categories, that form phase one of the shape of words project. The experiment descriptions also introduce new concepts, and cover some of the previously discussed ideas in more detail.
In the previous article, the shape of words, I described in general terms, a research program aiming at understanding natural language data through the lens of algebraic topology.
The central theme of the shape of words project is exploring to what degree topological structure plays a role in deriving linguistic unit representations, and how can topological constructs be employed for the purpose of gaining deeper insights into neural language models.
A better understanding of representation manifolds inherent to neural language models can lead to more informative or compressed representations.
Recent developments in deep learning hint at the utility of understanding topological structure of data in improving representational power of neural information processing systems.
For instance, in Welling et. al. show that augmenting the self-attention mechanism of transformer architectures with an inductive prior encoding roto-translational structure leads to significant gains in robustness for point cloud and graph data modeling.
The idea of encoding manifold structure by algebraically tying synaptic connection weights is at the core of advancements in neural artificial intelligence ().
I believe that augmentations to neural architctures informed by deep understanding of topological structure of data, will provide an ample source of future advancements in this AI.
In order to attempt answering the questions posed in the shape of words project, I first develop methods for assigning meaningful topology to the two sides of a language model: raw text data, and its vector space representations induced by the neural network.
For this purpose, two sets of techniques will be used.
On the corpus side, I construct a simplicial complex, that encodes word co-occurrence patterns.
On the embedding side, I construct Vietoris-Rips filtrations based on representations induced by the neural language model.
A starting observation I make here, is that these two structures must be naturally related.
This is because the language model induces representations via self-supervised back-propagation learning from masked sequences of words appearing in the corpus.
The representations that are useful for predicting masked words from their contexts, must therefore encode word co-occurrence patterns expressed by the n-grams extracted from the corpus.
The project progresses by exploring topological structure of the raw n-grams and their representations, investigating relationships between them, and later attempting to formalize conclusions in the language of Category Theory.
Before that is possible, a series of experiments needs to be done.
Those experiments are aimed at understanding the structure of topological manifolds associated to the corpus, as well as their vector space representations within neural language models.
The experiments also investigate learning dynamics, representations of sentences and documents, and the utility of topological methods for inducing more informative representations (resulting in model compression).
The following sections outline the goals of each experiment to be performed.
In this experiment, I will compute the word manifold homology of several synthetic corpora in order to gauge the behavior of the algorithm developed for this purpose.
The resulting analysis will form a baseline, before moving onto real natural language data.
I will perform the analysis for varying sizes of n-grams (which determine maximum possible dimensionality of the resulting simplicial complex), and qualitatively examine the outputs.
The main mathematical apparatus used here, will be homology of finite simplicial complexes computed using Smith normal form of the boundary map.
In this experiment, I will examine what kind of linguistic signal affects the topological structure of the word manifold the most.
The mathematical and algorithmic methods will be the same as in the previous experiment, but I will use natural language data instead.
The natural language corpora will be the moving piece, and they will be selected to ablate syntactic and semantic signal in the data.
The experiment has two parts.
In the first part, I construct word manifolds from corpora in two languages (English and French) that are translations of the same articles.
This is meant to keep semantic signal constant while changing the syntax.
In the subsequent part, I study documents from the same language (English) but taken from different styles of writing, and focused on different topics.
This is meant to keep the syntax constant while varying semantics.
I then compare the linguistic manifolds corresponding to varying these two dimensions of natural language data.
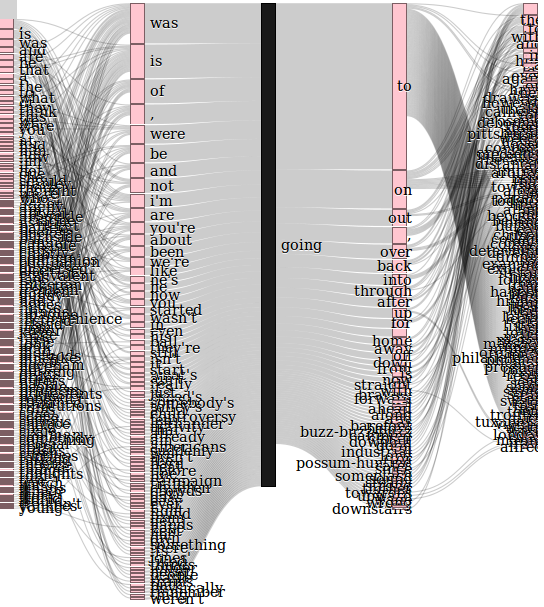
FIGURE 1Context visualization of the word going extracted from a 5-gram model of the Brown Corpus .
This experiment came from the realization that there are two complementary ways of viewing a corpus of text.
One is to consider words as the objects of study, and build structure from the relationships between words based on their surrounding contexts (figure 1 shows a visualization of a context extracted from data used in this experiment).
A dual view that I want to explore in this experiment leads to the construction of the context manifold.
This is another simplicial complex built from the same data as the word manifold in the previous experiments, but the atomic objects of study here are n-grams of words, which I call contexts.
The structure of the manifold is then induced from the relationships between contexts determined by the words that appear in them.
To exemplify this idea, it is useful to give a simple illustration.
Consider the following three 3-grams taken from some corpus of natural language text: "grass was green", "grass is green", "it was good".
We could look at the middle word in each 3-gram: "was", "is", "was".
The remaining two words are then the context of the middle word: "grass __ green", "grass __ green", "it __ good".
In the first view (focused on words), we could say that the word "was" and the word "is" are related because they share the same context "grass __ green".
In the second view (focused on contexts), we can say that the contexts "grass __ green" and "it __ good" are related because they share the same word "was".
The two views can be summarized as follows.
word manifold :
lowest dimension structures represent words
higher dimensional structures come from relationships between words as determined by contexts in which they appear
context manifold :
lowest dimension structures represent contexts
higher dimensional structures come from relationships between contexts as determined by words which can appear in them
This experiment will construct this dual manifold based on the same data from the previous word manifold experiments, and compare the differences in emergent topological structure.
In this experiment, I train a neural language model on corpora of synthetic and natural language text using the masked sequence prediction objective.
In this general task, the model is given sentences from the corpus with random words missing, and the task is to predict the missing words given their context.
In order to make the predictions, the model induces vector space representation of the corpus that is informative for approximating the word co-occurrence distribution present in its sentences.
The ambient space is high dimensional (I consider a range of values 50-500 dimensions), but the word embeddings form a point cloud in a neighborhood of a lower dimensional submanifold.
The goal of this experiment is to explore the topological features of this manifold by approximating it with a sequence of simplicial complexes of lower dimension.
This involves projecting the point cloud onto a lower dimensional space and clustering the preimages of an open cover in this projection.
I then associate a simplicial complex to this clustering, where 0-simplices are groups of words, and higher dimensional simplices provide a coarse sketch of their distribution within the high-dimensional embedding manifold.
This description is reductionist, and is meant to give more qualitative view of the data.
The following experiments investigate topological features of this manifold more directly (without employing this type of dimensionality reduction).
In order to have full access and understanding of the language model, and the ability to ablate contribution of it's parts, I construct the model from scratch using my own framework developed for this purpose.
The code used does not import any third party libraries but instead uses Basic Linear Algebra Subprograms to perform minimal required computation in a transparent way, which allows for full understanding of the representation induction process.
This will be beneficial to both myself, as I conduct the experiments, as well as to the readers and collaborators, as they will be able to get fuller understanding of the computational processes involved, and thus follow the arguments without requiring additional assumptions.
FIGURE 2Overview of the the empirical process used in this experiment. Blue nodes represent parts of the process involving human choices, and green nodes correspond to fully data-driven operations.
In this experiment, I study the representation manifold of the neural language model developed in the previous experiment more directly.
For this purpose, I employ the methodology of topological data analysis (see figure 2 for an overview diagram of the process).
In particular, I will compute persistent homology of the point cloud of vectors corresponding to the words of the corpus, in a convergent neural language model trained on this data.
There are various representation methods based on the idea of topological persistence.
I plan to look at a few canonical techniques such as persistence images () to represent the topological information in the embedding manifold.
Additionally, I will compare the homology of the word manifold and context manifold to the homology of the neural representation manifold induced from the same data.
In this experiment, I will examine the structure of local word neighborhoods within the embedding manifold.
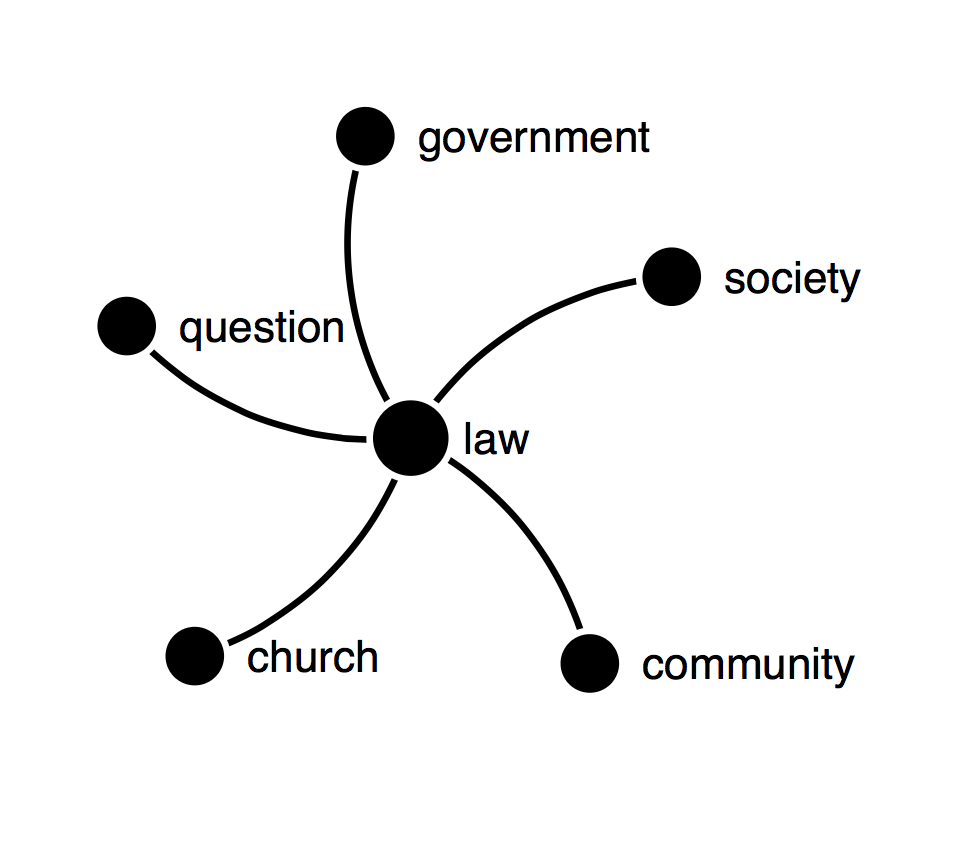
Given a word w, I define the n-star at w to be the undirected graph with a central vertex, corresponding to the word w, and n additional vertices - one for each of the n nearest neighbors of w under a neural embedding induced by the language model - together with n edges connecting the neighbor vertices to the central vertex associated to the root word w.
Figure 3 shows a 5-star at 'law' obtained from the Brown Corpus .
This structure is a basic building block for the inductive construction of Word Neighborhood Graph (WNG).
I now define the n-neighbors g-generations Word Neighborhood Graph around w - WNG(w, n, g) - by expanding each vertex in the n-star at w into a new n-star at that vertex, repeating the process inductively g times, and finally taking a quotient of the resulting graph by an equivalence relation which identifies vertices corresponding to the same words.
The last step (taking a quotient) collapses some vertices and creates multiple edges.
In general the graph grows, and forms nontrivial topology, because the nearest-neighbor operation does not commute - e.g.
in the Brown Corpus, the nearest neighbor of 'education' is 'religion', but the nearest neighbor of 'religion' is 'consciousness'.
Figure 4 shows WNG(3, 2, 'history').
FIGURE 35-star at the word 'law' computed from the Brown CorpusFIGURE 43-neighbors 2-generations word neighborhood of 'history'
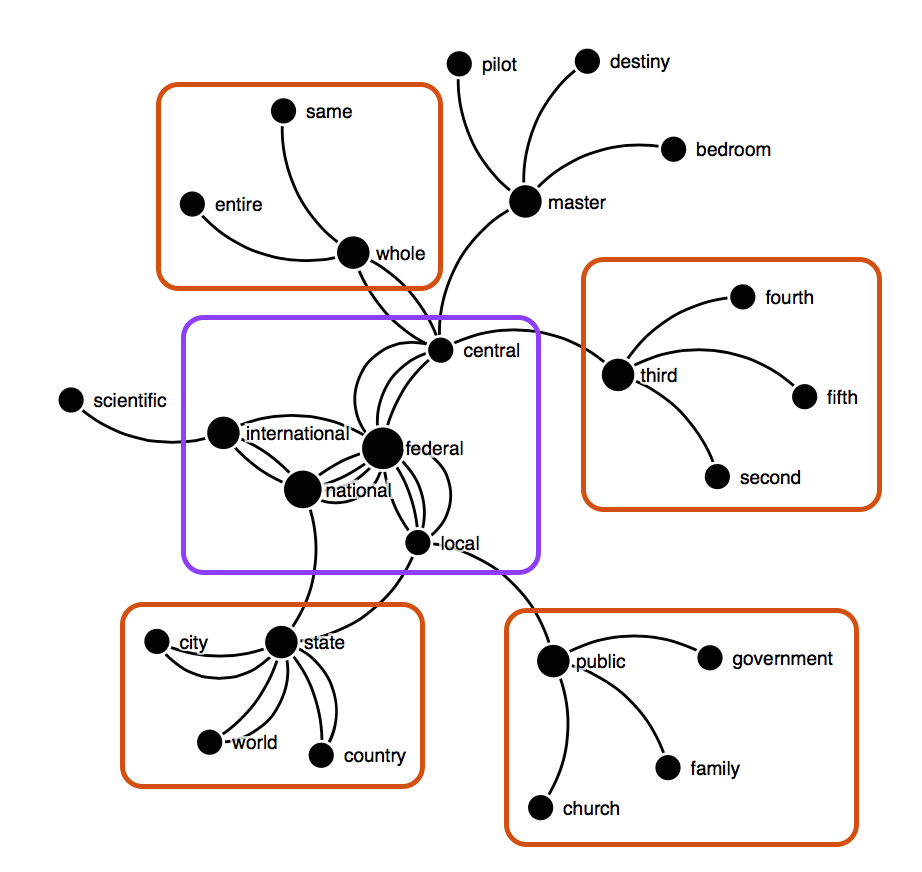
Collapsing the vertices to form multiple edges visually highlights strongly related groups of words like the set {'federal', 'national', 'central', 'local', 'international'} in figure 5.
I also highlight surrounding blocks of words forming coherent groups.
FIGURE 5WNG('federal', 3, 3) obtained from the Brown Corpus
I implemented a visualization tool in JavaScript, which allows me to explore a corpus in real time by generating word neighborhoods for each word in the corpus at varying levels of neighbors and generations.
The resulting graph is then embedded using an energy minimization algorithm on the plane . The figures shown here are generated using my tool.
The graph embedding algorithm used in my code is augmented with a center of gravity (located in the center of the canvas) so that the entire graph is attracted towards that point.
Each node can be dragged with a mouse and the graph reacts accordingly.
The nodes can also be pinned to the plane to separate them in case of many nodes overlapping.
Upon mouse-over the selected node, together with its direct neighbors, is highlighted and the rest of the graph is grayed-out.
This allows for more efficient exploration for larger graphs.
Each node has a label corresponding to the word in the corpus that it represents, and the size of the node is inversely proportional to the generation of the node.
When multiple links occur, the successive edges are drawn as Bezier curves with increasing curvature so that they don't overlap.
The user specifies a seed word to start with, the number of neighbors, and number of generations to expand.
The experiment builds on this construction as follows.
Starting with a given word token, I generate its n/g-expansion in the representation space induced by a neural language model.
I then construct a Vietoris-Rips filtration on the point cloud corresponding to this expansion.
Subsequently, I extract topological persistence diagrams for varying choices of the hyperparameters n and g.
I am particularly interested in the relative p-Wasserstein distances between diagrams corresponding to growing values of the hyperparameters.
The hypothesis I want to test is that those distances will become smaller, and at some point converge to 0.
When this happens, the topology of the growing neighborhoods stabilizes, meaning that further expanding the size of the neighborhood does not change the homotopy type of the manifold represented by the n/g-expansion.
I take this stable point as the definition of the homotopy type of a word neighborhood.
TOPOLOGICAL STRUCTURE OF RECURRENT STATE TRAJECTORIES
FIGURE 6We can reinterpret a time series of values as a geometric object by performing a sliding window embedding . The resulting point cloud can then be interpreted as noisy samples from an underlying manifold. The topology of this manifold can be studied using tools from computational algebraic topology. It reveals intrinsic properties of the original time series that are not easily captured by standard methods.
In this experiment, I will apply topological methods to modelling of time series associated with the hidden state vector of a gated recurrent language model.
Such models have a vector representation of the cell state, that is updated sequentially as data from a time series is fed into the system.
In deep learning NLP methods, this form of neural representation has been used to encode sentences and documents.
Vector representations of each word in a sentence are submitted into the recurrent cell, which evolves the hidden state.
We can then use the final hidden state, or some function (e.g. arithmetic mean) of all the states (after each word was processed) as a vector space representation of the entire sequence (e.g. a sentence from the corpus).
I am particularly interested in analyzing the structure of such sequences (i.e. sentence representations in a recurrent language model) from a topological perspective.
For this purpose, I reinterpret a time series in a geometric way, by associating a topological manifold to the hidden state trajectory.
This procedure involves two steps: sliding window embedding, and the construction of a simplicial complex.
The first step reinterprets the time series as a point cloud in a different space, where axes correspond to samples within the window.
The second step then constructs a topological space from the resulting point cloud.
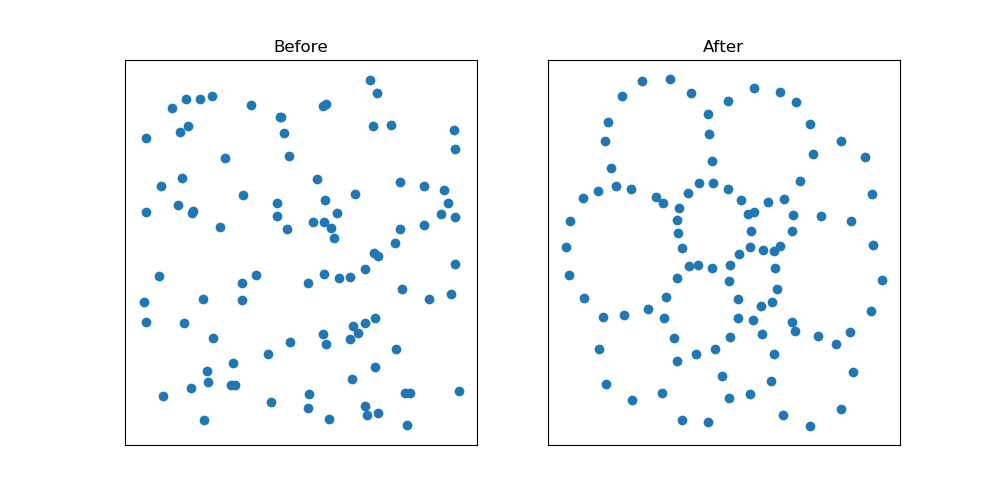
FIGURE 7Point cloud of word vectors. Projection from a high dimensional distributed representation onto a graph via a spectral embedding.
In this experiment, I will use the tools from previous experiments to analyze how various topological markers evolve during the induction process of language representations.
Concretely, I will train neural language models on corpus data while freezing embedding layers at various timesteps and computing topological descriptors.
I will then analyze how the topology of linguistic unit representations evolves as the model is trained.
The purpose of this experiment is to test if there are topological patterns of convergence, and if they can be used to identify overfitting and derive early stopping heuristics for neural language models.
FIGURE 8A random point cloud in \mathbb{R}^2 conditioned on a homotopy type of a manifold with the first homology group of high rank.
In this experiment, I investigate if the knowledge about the structure of natural language data learned in previous experiments can be used to augment a neural architecture in a way that could take advantage of topological information.
In particular, I am interested in testing the hypothesis that homotopy type of the word and embedding manifolds, can carry useful linguistic information, and be used as priors in language model training.
For this purpose I implement a form of regularization that encourages the representation manifold of the language model to approximate a pre-determined homotopy type.
I then perform experiments, where I condition a new untrained model on the topological information contained in the corpus, and measure differences in convergence times, as well as power of the derived representations.
I call this procedure topological conditioning, and the hypothesis tested in this experiment is whether it can lead to more informative representations or improved convergence for neural language models.
FIGURE 9A sample from the HotPotQA dataset used in document representation experiment. This is a question answering dataset featuring natural, multi-hop questions, with strong supervision for supporting facts to enable more explainable question answering systems. It is collected by a team of NLP researchers at Carnegie Mellon University, Stanford University, and Université de Montréal.
In this experiment, I incorporate topological information on supra-lexical level.
In particular, I introduce topological priors into document representation, starting with a definition of a 1-skeleton on larger substrings within the text.
This can be done in practice via an adjacency matrix that determines relationships between parts of the document (e.g. sentences or paragraphs).
Majority of the prior experiments in this project focus on intrinsic evaluation of language representations.
The objective of this experiment is to evaluate topologically enriched document representations extrinsically.
Extrinsic evaluation, does not test directly for linguistic information in the embedding manifold, but rather examines induced representations by using them as input to downstream NLP tasks, under the assumption that performance on real-world tasks can be used as a proxy for the amount of linguistic information contained within.
For this purpose, I introduce a test model for multi-document question answering.
I test the contribution of topological information by implementing a topologically informed QA system and evaluating it on the HotPotQA Dataset, .
This is a multi document question answering dataset where documents may or may not be related to the question. Additionally, some questions may require inferring from "multiple hops" within documents to reach a conclusive answer (see figure 9 for an example).
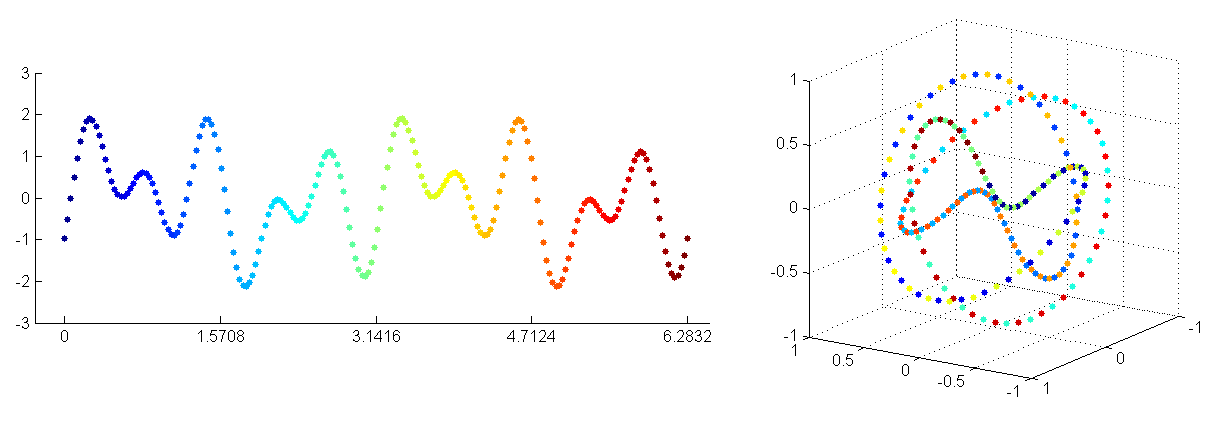
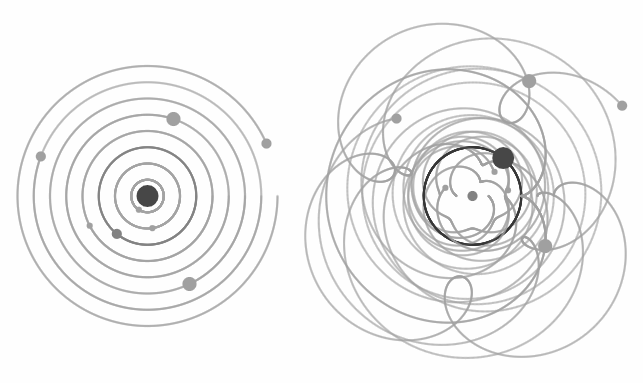
FIGURE 10Heliocentric (left) vs geocentric (right) description of the solar system.
The hypothesis I want to test in this experiment is that topologically informed representations can produce more sustainable NLP systems by significantly reducing model complexity (similarly to how understanding the topology of planetary motion allows us to reparametrize geocentrism into heliocentrism, leading to significant model compression - as pictured in figure 10), and hence lowering the cost of model training.
Remarks
This article is an idea paper on a work in progress.